
مقدمه
هوش مصنوعی به سرعت در حال تحول است و مدلهای زبانی بزرگ (LLM) توانستهاند تواناییهای چشمگیری در پردازش زبان طبیعی ارائه دهند. با این حال، یکی از محدودیتهای اصلی این مدلها، دسترسی محدود به اطلاعات بهروز و واقعی است. RAG (Retrieval-Augmented Generation) به عنوان یک راهکار ترکیبی، این مشکل را حل میکند. و مدلهای زبانی را با منابع خارجی اطلاعات تقویت میکند تا پاسخهای دقیقتر، قابل اعتمادتر و مبتنی بر داده ارائه شوند.
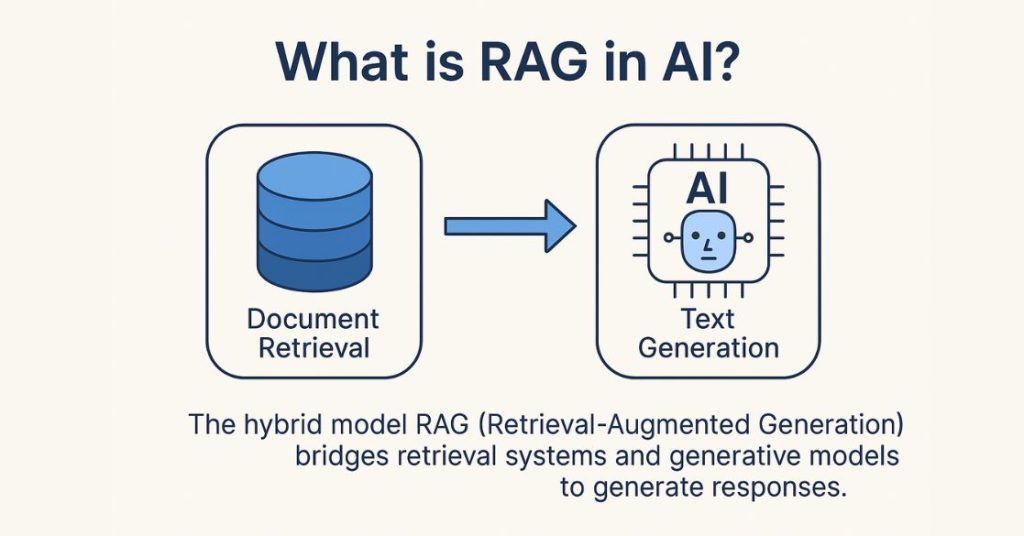
RAG چیست؟
RAG (Retrieval-Augmented Generation) یک معماری در هوش مصنوعی است که دو فرآیند اصلی را ترکیب میکند:
-
بازیابی اطلاعات (Retrieval): سیستم مستندات یا پایگاه داده را جستجو میکند تا اطلاعات مرتبط با پرسش کاربر پیدا شود.
-
تولید محتوا (Generation): مدل زبانی (مثل GPT یا BERT-based) با استفاده از اطلاعات بازیابیشده، پاسخ دقیق و طبیعی تولید میکند.
این فرآیند باعث میشود که مدل نه تنها بر پایه دانش داخلی خود پاسخ دهد، بلکه به دادههای واقعی و بهروز دسترسی داشته باشد.
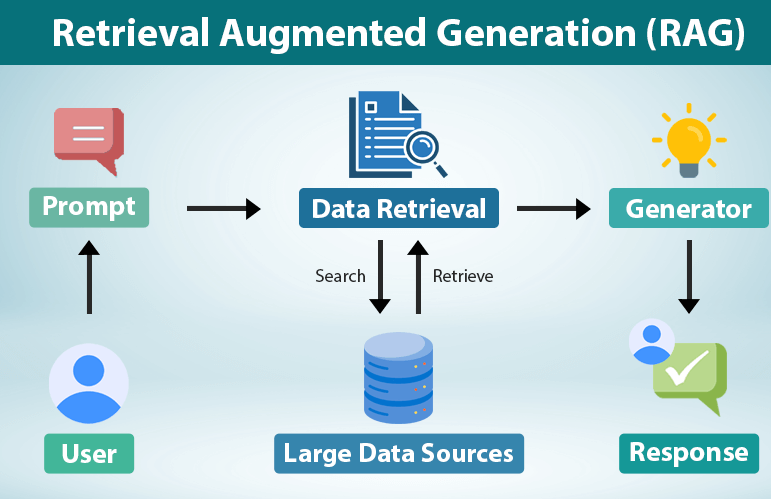
ساختار فنی RAG
معماری RAG معمولاً شامل سه بخش اصلی است:
1. Encoder (رمزگذار)
-
پرسش کاربر به یک بردار عددی (embedding) تبدیل میشود.
-
مدلهایی مانند BERT، RoBERTa یا Sentence Transformers برای تولید embedding استفاده میشوند.
-
این بردار نشاندهنده مفهوم پرسش است و برای جستجوی مشابهت در پایگاه داده استفاده میشود.
2. Retriever (سیستم بازیابی)
-
سیستم، بردار پرسش را با بردارهای مستندات موجود در پایگاه داده مقایسه میکند.
-
الگوریتمهای مشابهت برداری مانند FAISS یا Annoy نزدیکترین مستندات را پیدا میکنند.
-
مدل از مستنداتی استفاده میکند که بالاترین امتیاز مشابهت را دارند.
3. Generator (مدل تولید)
-
اطلاعات بازیابیشده به مدل زبانی داده میشوند.
-
مدل، پاسخ نهایی را تولید میکند که هم معنیدار و هم مبتنی بر مستندات واقعی است.
-
این فرآیند معمولاً از معماریهای Transformer استفاده میکند.
کاربردهای RAG در هوش مصنوعی
RAG به دلیل ترکیب تواناییهای بازیابی اطلاعات و تولید متن، کاربردهای گستردهای دارد:
-
سیستمهای پرسش و پاسخ پیشرفته (Advanced QA):
کاربران میتوانند سوالات تخصصی بپرسند و پاسخهای دقیق دریافت کنند، حتی اگر دانش مدل محدود باشد. -
چتباتهای سازمانی (Enterprise Chatbots):
دسترسی به مستندات داخلی شرکت و تولید پاسخهای مبتنی بر داده واقعی. -
موتورهای جستجوی هوشمند (Intelligent Search Engines):
ترکیب جستجو و تولید متن برای ارائه خلاصه یا پاسخ مستقیم به کاربران. -
تحلیل و تولید گزارشهای علمی و تحقیقاتی:
جمعآوری دادههای چند منبع و تولید محتوا با استناد دقیق.
مزایای استفاده از RAG
-
دقت بالاتر: پاسخها مبتنی بر مستندات واقعی هستند، نه صرفاً حافظه مدل.
-
بهروز بودن اطلاعات: امکان اتصال به پایگاه دادههای خارجی یا API برای دسترسی به دادههای زنده.
-
قابلیت انعطاف بالا: میتوان با منابع مختلف و زمینههای تخصصی سازگار شد.
-
کاهش تولید اطلاعات نادرست (Hallucination): استفاده از مستندات واقعی باعث افزایش اعتماد به پاسخها میشود.
چالشها و محدودیتها
با وجود مزایای زیاد، RAG چالشهایی نیز دارد:
-
نیاز به پایگاه داده گسترده و بهروز: برای عملکرد بهتر، مستندات باید کامل و دقیق باشند.
-
پیچیدگی پردازشی: بازیابی و تولید همزمان نیازمند منابع محاسباتی بالاست.
-
مدیریت مشابهت و ابهام: گاهی مستندات بازیابیشده مرتبط نبوده یا چندپاره باشند.
-
ملاحظات امنیت و حریم خصوصی: دسترسی به دادههای حساس نیازمند مدیریت دقیق است.
نتیجهگیری
RAG یک تحول مهم در دنیای هوش مصنوعی و پردازش زبان طبیعی است. با ترکیب تواناییهای بازیابی اطلاعات و تولید محتوا، این معماری به مدلها اجازه میدهد تا پاسخهای دقیقتر، قابل اعتمادتر و مبتنی بر داده ارائه دهند. برای سازمانها، محققان و توسعهدهندگان AI، استفاده از RAG میتواند کیفیت سیستمهای پرسش و پاسخ، چتباتها و موتورهای جستجو را به طور چشمگیری افزایش دهد.
سوالات متداول
RAG چه تفاوتی با مدلهای سنتی LLM دارد؟
مدلهای سنتی فقط بر دانش داخلی خود تکیه دارند، اما RAG با دسترسی به مستندات خارجی پاسخ دقیقتری ارائه میدهد.
آیا RAG برای دادههای بهروز مناسب است؟
بله، زیرا میتوان آن را به پایگاه دادههای زنده و APIهای خارجی متصل کرد.
آیا استفاده از RAG پیچیده است؟
معماری آن پیچیدهتر از مدلهای استاندارد LLM است و نیاز به منابع محاسباتی و دادههای سازمانیافته دارد.
نمونه ابزارها و کتابخانههای RAG چیست؟
برخی ابزارها شامل HuggingFace RAG, FAISS, ElasticSearch و مدلهای مبتنی بر Transformers هستند.

